Redshift a Databricks - Parte 1: Por qué y cómo iniciar tu migración
Bienvenidos a nuestra guía completa sobre la migración de Amazon Redshift a Databricks. Para proporcionar una comprensión exhaustiva de los aspectos tanto estratégicos como técnicos de esta migración, hemos estructurado esta guía en dos entradas detalladas.
Parte 1 (Por qué y cómo iniciar tu migración a Databricks): En la primera parte, profundizaremos en los conceptos fundamentales detrás de la migración. Exploraremos las razones por las que las organizaciones están cambiando a Databricks, los beneficios que ofrece sobre Redshift, y las consideraciones clave a tener en cuenta durante la fase de planificación. Esta sección está diseñada para ayudarte a entender el "por qué" y el "qué" antes de pasar al "cómo".
Parte 2 (Guía de implementación técnica): La segunda parte se centrará en los pasos técnicos necesarios para ejecutar la migración con éxito. Proporcionaremos una guía paso a paso que cubre métodos de transferencia de datos, conversión de esquemas, optimización de consultas y mejores prácticas para asegurar una transición sin problemas. Esta sección está orientada a profesionales técnicos que están listos para sumergirse en el "cómo" del proceso de migración.

Fuente: SunnyData
Entendiendo Amazon Redshift
Amazon Redshift es un data warehouse lanzado por AWS en octubre de 2012, que ha sido bien recibido en el mercado, impulsado principalmente por el éxito de AWS como proveedor de servicios en la nube y la decisión de sus clientes de utilizar los servicios nativos de AWS. Según informes de Forrester del cuarto trimestre de 2018, Amazon Redshift tenía el mayor número de implementaciones de data warehouse en la nube (alrededor de 6.500), posicionándose por delante de otros data warehouses tradicionales como BigQuery, Snowflake y Teradata.
Desde una perspectiva técnica, Amazon Redshift está diseñado para manejar grandes volúmenes de datos y realizar análisis complejos de manera eficiente. Emplea una arquitectura de procesamiento masivo en paralelo (MPP) para distribuir y procesar datos a través de múltiples nodos, y utiliza una estructura de almacenamiento columnar para maximizar la eficiencia de lectura de datos al acceder solo a las columnas relevantes necesarias para una consulta.

La versión inicial de Redshift se basó en una versión anterior de PostgreSQL 8.0.2, sobre la cual Amazon ha introducido numerosas mejoras y evoluciones a lo largo del tiempo.
Redshift está diseñado para integrarse perfectamente con otros servicios en el ecosistema AWS—Glue, EMR, Lake Formation—y para comunicarse con varias fuentes de almacenamiento como Amazon Aurora y Amazon S3. Esta integración ha sido un factor clave en la adopción de Redshift por parte de muchas empresas durante su proceso de migración a la nube.
Desafíos con Amazon RedShift
Amazon Redshift tiene la arquitectura más antigua entre los primeros data warehouses en la nube y, como resultado, carece de algunas características que se popularizaron más tarde y que los usuarios modernos ahora consideran esenciales, como la separación entre cómputo y almacenamiento. Esto se debe a que Amazon adquirió el código fuente de ParAccel (que luego fue adquirido por Actian), basado en una versión anterior de PostgreSQL (como se mencionó en el párrafo anterior). La decisión de construir sobre esta base de código heredada y, por lo tanto, heredar limitaciones fundamentales ha llevado a críticas recurrentes dentro de la comunidad, donde los usuarios expresan insatisfacción con aspectos como el rendimiento y la relación costo-efectividad.
Amazon Redshift tiene la arquitectura más antigua
He leído comentarios en línea que critican a Amazon Redshift, diciendo cosas como: "Es horrible", "si tu uso promedio de CPU es del 10%, estás pagando 5 veces más que con otra plataforma", "Redshift no es malo, pero es peor que todo lo demás", "la documentación es mala" y "Amazon no está invirtiendo en él, y se está quedando atrás". Hay otros comentarios que no citaré para mantener el tono formal del artículo.
Desde mi perspectiva, si bien muchas de estas críticas son válidas, creo que la reputación que ha adquirido Amazon Redshift es algo injusta si no consideramos el contexto. Es importante entender que es un desafío para cualquier proveedor de servicios en la nube ofrecer soluciones que sean líderes en todos los aspectos. La clave es proporcionar un ecosistema integrado que pueda satisfacer diversas necesidades, incluso si no todos los servicios son los mejores en la industria.

De hecho, muchas empresas que comenzaron su proceso de adopción de la nube con AWS, migrando sus aplicaciones, encontraron que Amazon Redshift era un servicio adecuado para aprovechar sus datos. Principalmente porque cumplía con el objetivo que tenían las empresas hace años: generar informes y realizar consultas complejas sin afectar sus bases de datos de producción.
Arquitectura heredada y limitaciones de cómputo-almacenamiento
Amazon Redshift, como mencionamos, tiene una arquitectura más antigua en comparación con plataformas más modernas como Databricks o Snowflake. Una limitación significativa es la falta de separación completa entre cómputo y almacenamiento. En plataformas más nuevas, el cómputo y el almacenamiento están desacoplados, lo que significa que pueden escalar independientemente según las demandas de carga de trabajo. Esto permite una mayor flexibilidad y eficiencia de costos, ya que los usuarios pueden asignar solo los recursos que necesitan sin sobreaprovisionamiento.
Si bien las instancias RA3 de Redshift introducen cierto nivel de separación al permitir que los nodos de cómputo escalen mientras almacenan en caché solo los datos requeridos localmente, la arquitectura todavía vincula las operaciones de cómputo demasiado estrechamente con el almacenamiento en ciertos escenarios. Esto resulta en ineficiencias, particularmente para workloads fluctuantes o cuando se requiere el aislamiento de recursos de cómputo. En Redshift, no es posible aislar diferentes workloads sobre los mismos datos de manera tan eficiente como con arquitecturas completamente desacopladas, quedando por detrás de sistemas más adaptables como Databricks.

Escalabilidad limitada: Incluso con instancias RA3, Redshift tiene dificultades para escalar eficientemente para alta concurrencia. Solo puede poner en cola un máximo de 50 consultas, lo que puede causar retrasos durante workloads pico.
Limitaciones de concurrencia: La capacidad de Redshift para manejar múltiples workloads concurrentemente es limitada, especialmente bajo uso intensivo, lo que puede resultar en un rendimiento degradado.
Problemas de rendimiento: Redshift no funciona significativamente mejor que otros data warehouses en la nube en evaluaciones comparativas. Carece de soporte para índices y optimización integral de consultas, lo que dificulta lograr análisis de baja latencia a escala.
Altos costos debido al uso ineficiente de recursos
Uno de los inconvenientes más notables de Amazon Redshift es su potencial de altos costos operativos, particularmente cuando los recursos de cómputo no se utilizan completamente. Redshift requiere que los usuarios aprovisionen clústeres basados en el uso máximo anticipado. Sin embargo, si el uso real es menor (por ejemplo, si la utilización de CPU promedia por debajo del 20%, quizás estés pagando 5 veces más que con otra plataforma), las organizaciones están efectivamente pagando por recursos inactivos.

A diferencia de Databricks, que puede escalar dinámicamente los recursos de cómputo según la demanda en tiempo real, Redshift no reduce automáticamente la capacidad durante períodos de baja actividad. Esto puede llevar a un sobreaprovisionamiento y costos más altos. Por ejemplo, las empresas que configuran Redshift para satisfacer las demandas de alto rendimiento durante los momentos pico pero no utilizan constantemente esa capacidad, probablemente terminarán pagando más de lo que pagarían con una plataforma más flexible como Databricks.
El modelo de costos de Redshift es más estático y menos adaptable a workloads variables, lo que resulta en costos operativos significativamente más altos para negocios con demandas fluctuantes.
Ingesta centrada en lotes: Redshift está optimizado para la ingesta por lotes pero carece de soporte robusto para la ingesta continua de datos, haciéndolo menos adecuado para análisis en tiempo real, especialmente en comparación con Databricks, que sobresale en tales escenarios.
Alto costo por baja utilización: Redshift puede volverse particularmente costoso cuando la utilización es baja, ya que la plataforma no escala eficientemente los recursos para igualar el uso real.
Falta de capacidades de consulta interactiva: Redshift es menos efectivo para consultas interactivas y ad-hoc, especialmente en comparación con data warehouses más modernos optimizados para tales casos de uso.
Limitaciones en lenguajes de programación
Si bien Redshift está optimizado para SQL, su soporte para otros lenguajes como Python es restringido. Aunque Python puede usarse a través de Funciones Definidas por el Usuario (UDFs), estas no están completamente integradas y son más limitadas en comparación con plataformas que soportan nativamente lenguajes adicionales, reduciendo la flexibilidad para los desarrolladores.
Soporte limitado para datos semi estructurados
Redshift permite el uso de formatos como JSON, pero no está optimizado para manejar grandes volúmenes de datos semiestructurados. Las consultas complejas en estos formatos pueden ser lentas, afectando el rendimiento en comparación con plataformas más modernas que están específicamente optimizadas para el procesamiento de datos semiestructurados.
Complejidad en la gestión
Redshift requiere una intervención manual significativa para la configuración y ajuste del rendimiento. Si bien ofrece muchas opciones de optimización, estas demandan un alto nivel de administración manual, haciéndolo más desafiante en comparación con plataformas que proporcionan más automatización y facilidad de gestión.
Consultas en tiempo real y análisis de flujos
Redshift no está bien optimizado para consultas en tiempo real o análisis continuos de flujos. Si bien maneja operaciones por lotes eficientemente, su rendimiento sufre significativamente cuando se requiere procesamiento en tiempo real, haciéndolo menos adecuado para aplicaciones que necesitan respuestas inmediatas.
Rendimiento inconsistente con datos complejos
A medida que los conjuntos de datos crecen en tamaño y complejidad, Redshift tiende a tener dificultades para mantener un rendimiento consistente. Las consultas a menudo se vuelven más lentas sin ajustes manuales frecuentes, como la optimización a través de claves de ordenación y distribución, requiriendo un esfuerzo considerable en gestión y ajuste.
Entonces, ¿por qué migrar de Redshift a Databricks?
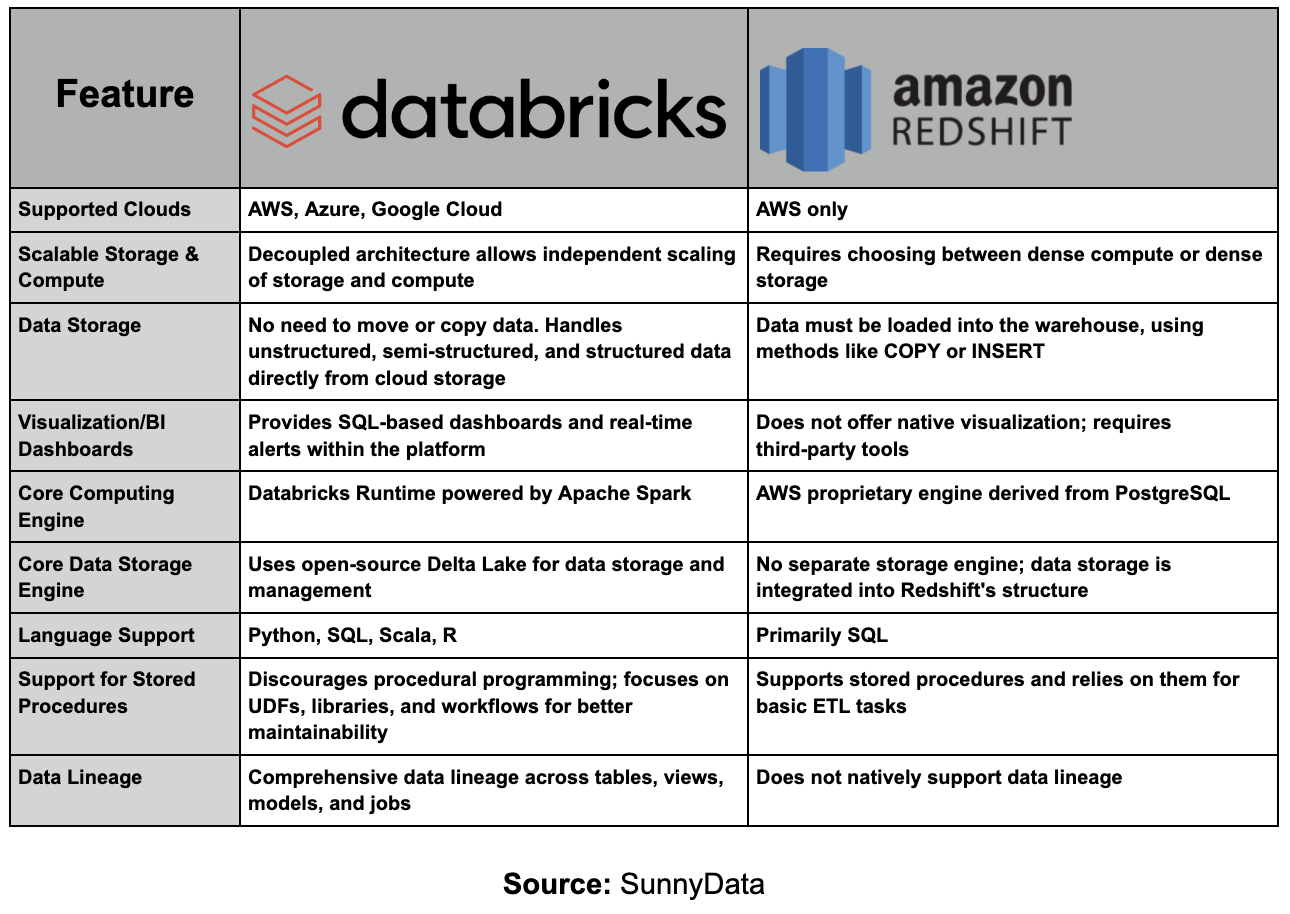
La comparación entre Amazon Redshift y Databricks no es completamente justa debido a las diferencias fundamentales en sus enfoques y propósitos. Amazon Redshift es un data warehouse, principalmente diseñado para almacenar y procesar grandes volúmenes de datos estructurados, centrándose en consultas analíticas y generación de informes.
En contraste, Databricks es una plataforma Lakehouse, que combina los mejores aspectos de los data lakes y los data warehouses y está diseñada para manejar todo el ecosistema de datos, desde la ingesta y almacenamiento hasta análisis avanzados e inteligencia artificial.
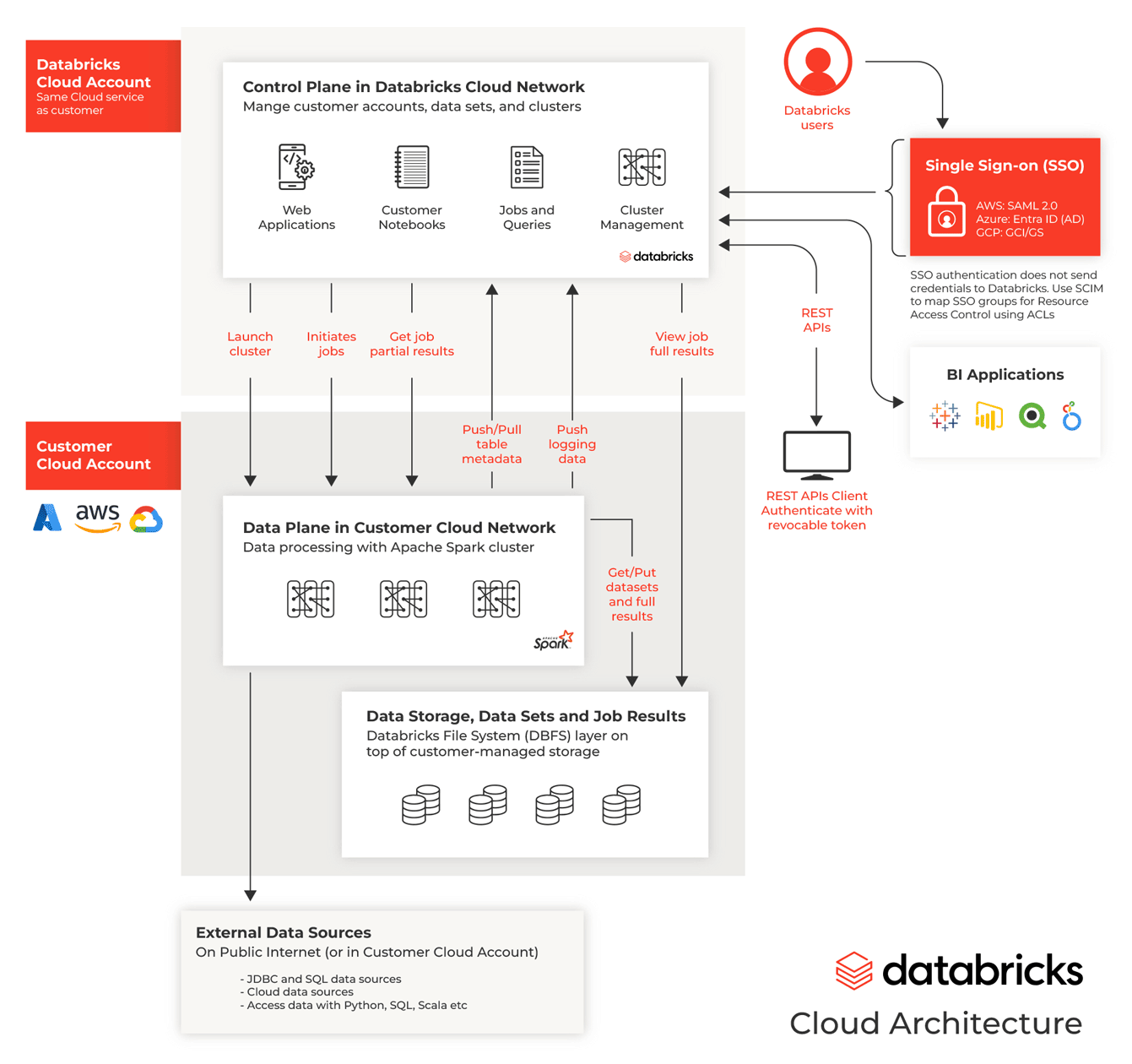
En este sentido, una comparación más apropiada sería entre Amazon Redshift y Databricks SQL, que es la capa específica de Databricks para consultas SQL y análisis de datos estructurados. Sin embargo, incluso esta comparación no es completamente precisa, ya que Databricks tiene un enfoque mucho más integral. Databricks no solo ofrece capacidades SQL para análisis de datos estructurados, sino que también soporta el procesamiento de datos no estructurados, streaming, machine learning y análisis en tiempo real, posicionándose como una plataforma unificada que cubre todo el ciclo de vida de los datos.
En contraste, Redshift está más enfocado en el almacenamiento tradicional de datos estructurados y análisis.
Databricks aborda efectivamente muchos desafíos enfrentados por los profesionales de datos a través de su diseño agnóstico, ofreciendo versatilidad inigualable en dimensiones críticas:
En primer lugar, es agnóstico en cuanto a la nube, integrándose perfectamente con AWS, Azure y Google Cloud. Esta flexibilidad permite a las organizaciones elegir la infraestructura en la nube que mejor se adapte a sus necesidades sin estar atados a un solo proveedor—una característica invaluable para empresas que operan en entornos multi-nube o que se adaptan a tecnologías en la nube en evolución.

En segundo lugar, Databricks es agnóstico en cuanto a lenguajes de programación, soportando Python, R, SQL y Scala—incluso dentro del mismo notebook. Esto empodera a profesionales de datos de diferentes orígenes para colaborar más efectivamente, fomentando un ambiente inclusivo donde cada miembro del equipo puede trabajar en su lenguaje preferido. Ya sea construyendo modelos complejos de machine learning o ejecutando consultas SQL a gran escala, Databricks asegura que las herramientas necesarias estén fácilmente disponibles.
Además, Databricks sobresale tanto en procesamiento por lotes como en ingesta de datos en tiempo real debido a su arquitectura Delta Lake, que asegura alto rendimiento y confiabilidad. Ser agnóstico a los modos de procesamiento es crucial para organizaciones que necesitan soportar tanto análisis de datos históricos como toma de decisiones en tiempo real dentro de la misma plataforma.

Adicionalmente, Databricks es agnóstico en cuanto a roles, atendiendo a ingenieros de datos, científicos de datos y analistas de negocio al proporcionar una plataforma unificada para construir pipelines ETL, ejecutar modelos de machine learning y conducir análisis avanzados.
Finalmente, Databricks ofrece excelente escalabilidad y gestión de costos. Su arquitectura separa cómputo y almacenamiento, permitiendo a las empresas escalar recursos independientemente y optimizar costos. La plataforma también soporta computación serverless, mejorando su capacidad para escalar eficientemente basado en las demandas de carga de trabajo. Esto asegura que las empresas puedan mantener un alto rendimiento mientras mantienen los costos bajo control, incluso a medida que crecen sus necesidades de procesamiento de datos.

Qué considerar antes de migrar de Amazon Redshift a Databricks
Esta segunda sección del blog continuará la próxima semana, ya que indudablemente existe una fuerte conexión entre el 'Qué' y el 'Cómo' de la migración. Por ahora, evitaremos profundizar en detalles técnicos.

Introducción al 'Qué' de la migración
Migrar con éxito de Amazon Redshift a Databricks requiere una planificación y ejecución cuidadosas. Un enfoque bien estructurado ayuda a minimizar riesgos y asegura una transición sin problemas.
El camino de migración óptimo dependerá de varios factores, incluyendo:
Arquitectura actual: Una de las consideraciones más importantes al planificar una migración es entender la arquitectura existente, incluyendo dependencias de otros servicios AWS y herramientas de terceros. Amazon Redshift, como data warehouse, a menudo depende de un ecosistema más amplio para funcionar óptimamente.
Por ejemplo, Redshift típicamente se usa junto con AWS Glue para procesos de ingesta de datos y ETL, o con AWS Lake Formation para catalogación y gobernanza de datos. Databricks se integra bien con herramientas como Glue o Amazon Kinesis para ingesta de datos en tiempo real, y muchos de estos artefactos pueden reutilizarse (profundizaremos en esto la próxima semana). AWS S3 también se usa comúnmente para almacenamiento de datos, sirviendo como columna vertebral para almacenar datos crudos, procesados y analíticos tanto para flujos de trabajo de Redshift como de Databricks.
Tipos de workload: El tipo de workload que se ejecutan en Redshift también jugará un papel importante en la formación del enfoque de migración. Redshift es principalmente un data warehouse diseñado para consultas estructuradas y analíticas, a menudo soportando dashboards de BI, procesos ETL y análisis por lotes. Sin embargo, las organizaciones cada vez más necesitan plataformas que puedan manejar workloads diversas, incluyendo pipelines de machine learning (ML), procesamiento de datos en tiempo real y consultas ad-hoc de datos semiestructurados.

Criticidad para el negocio: Los casos de uso críticos para el negocio necesitan atención especial durante la migración, ya que cualquier interrupción en estos flujos de trabajo puede tener consecuencias significativas. Por ejemplo, una institución financiera que utiliza Redshift para generar informes de cumplimiento regulatorio o dashboards de BI para toma de decisiones en tiempo real necesitará planificar cuidadosamente la migración para evitar tiempo de inactividad o degradación del rendimiento.
Para tales casos de uso críticos, un enfoque de migración por fases —migrar primero workloads no críticos— podría ser la mejor estrategia. Esto permite a las organizaciones probar y validar el proceso de migración en tareas menos esenciales antes de mover workloads fundamentales.
Proyectos en curso: Es importante alinear el cronograma de migración con otros proyectos en curso o planificados para minimizar el riesgo de interrupción. En algunos casos, la migración podría necesitar ser retrasada o segmentada para acomodar otras iniciativas de alta prioridad. Por ejemplo, si hay lanzamientos importantes de productos o auditorías regulatorias ocurriendo durante la migración, podría ser prudente pausar o dividir la migración en fases más pequeñas.
Objetivos de migración: Definir claramente los objetivos de la migración es crítico para su éxito. Ya sea que el objetivo sea reducir costos, cumplir con una fecha límite de cambio, o mejorar capacidades (como habilitar machine learning o análisis en tiempo real), estos objetivos guiarán cada etapa del proceso de migración.

La reducción de costos es a menudo un motivador importante, ya que el modelo de precios de Redshift requiere que las organizaciones aprovisionen clústeres por adelantado, llevando a posible sobreaprovisionamiento y costos más altos. Databricks ofrece precios más flexibles, permitiendo que cómputo y almacenamiento escalen independientemente, lo que puede reducir significativamente los costos para workloads que fluctúan en intensidad.
Estrategias de migración
Si bien hay dos estrategias principales para migrar de Amazon Redshift (o cualquier otra plataforma) a Databricks —una migración de tipo "big-bang" y una migración por fases— nuestro enfoque estará en el enfoque por fases. La estrategia de migración por fases es particularmente relevante para la gran mayoría de los clientes, ofreciendo varias ventajas que la convierten en el método preferido para la mayoría de los escenarios.
La migración por fases implica migrar datos y workloads en etapas, como por casos de uso específicos, esquemas o pipelines de datos. Este enfoque mitiga riesgos, demuestra progreso incremental y permite a las empresas validar y ajustar su estrategia de migración según sea necesario. Para organizaciones con arquitecturas de datos complejas, múltiples bases de datos o varios equipos de negocio que dependen de datos, una migración por fases proporciona la oportunidad de gestionar la transición sin interrumpir las operaciones en curso.
Si bien una migración de tipo "big-bang" puede ser más rápida, generalmente es adecuada para entornos más simples con huellas de datos más pequeñas o cuando el alcance de la migración es limitado. Además, en algunos casos especializados, como migraciones de software desde plataformas como SAS, un enfoque de "big-bang" podría ser necesario debido a restricciones de licenciamiento. Sin embargo, tales escenarios no se aplican a Amazon Redshift, que no involucra problemas de licenciamiento. Como resultado, la migración por fases es una estrategia mucho más segura y flexible para la mayoría de los usuarios de Redshift.

Antes de lanzar completamente el proyecto (Fase 5) y definir la estrategia de bajo nivel, inicialmente nos enfocaremos en las fases anteriores. Primero, necesitamos entender el estado actual y los objetivos (Fase 1), seguido por el diseño de la solución (Fase 2), y luego proponer una estrategia de migración clara (Fase 3). El objetivo inicial será implementar un piloto productivo (Fase 4) que valide la viabilidad del proyecto, particularmente en términos de tiempo y retorno de inversión (ROI), llevando a la ejecución completa del proyecto (Fase 5).
Cada una de estas fases será detallada en la próxima entrada del blog con conocimientos técnicos más profundos, pero por ahora, nos enfocaremos en la fase inicial.
Fase 1: Descubrimiento
La mejor manera de abordar una fase de Descubrimiento es a través de una combinación de personal experimentado con conocimiento previo de migración y el uso de aceleradores que simplifican el proceso de recopilación de información de la plataforma de origen. Esto, junto con prácticas y metodologías establecidas, ayuda a estructurar adecuadamente las acciones necesarias. Por ejemplo, Databricks proporciona cuestionarios que ayudan a recopilar datos clave, como identificar las máquinas en Redshift para configurar los clústeres equivalentes en Databricks.
Evaluando la situación actual

Amazon Redshift Profiler - Es altamente recomendable utilizar una herramienta aceleradora para obtener una comprensión clara de tu entorno Amazon Redshift, permitiendo una planificación de migración más efectiva. Databricks proporciona aceleradores incorporados específicamente diseñados para mapear el sistema de origen y entregar un análisis completo.
El Redshift Profiler examina elementos clave como tipos de carga de trabajo, procesos ETL de larga duración y patrones de acceso de usuarios, ofreciendo un desglose detallado de la complejidad del sistema—categorizado como alto, medio o bajo. Esto permite la priorización de workloads y ayuda a identificar desafíos potenciales en el proceso de migración.
Este tipo de aceleradores proporcionan visibilidad crítica en bases de datos y pipelines que pueden aumentar los costos o incrementar la complejidad, haciéndolos ideales para organizaciones que buscan optimizar el rendimiento y reducir los riesgos de migración.
Convertidores de código estáticos vs. acelerador basado en GenAI de SunnyData para migración ETL/EDW
El enfoque típico utilizado por la mayoría de las firmas consultoras para la conversión de código ETL a menudo se basa en herramientas estáticas (varias en el mercado) junto con la asignación de muchos recursos humanos al problema, lo que resulta en proyectos de conversión costosos ($$$$) y largos.
En este método tradicional, software convertidor estático codificado se utiliza para analizar el repositorio de código ETL y planificar el esfuerzo del proyecto. Si bien la conversión de código se realiza a través de un convertidor semi-automatizado, todavía requiere el soporte de un integrador de sistemas (SI) para abordar brechas de conversión y conducir pruebas, añadiendo una capa extra de complejidad al proceso.
Este método depende fuertemente de la experiencia manual para asegurar que los scripts y procesos ETL sean correctamente transformados y validados.
En contraste, el enfoque de SunnyData aprovecha GenAI para la conversión de código combinado con nuestra IP interna, lo que reduce la carga de costo y tiempo en migraciones EDW complejas. Aprovechamos herramientas GenAI (como Claude 2.0, DBRX y ChatGPT) para descubrir, evaluar y convertir la lógica de negocio central, lo que acelera y reduce el cronograma de migración EDW y la carga de costos en migraciones:
Automatizar descubrimiento y documentación: Los LLMs pueden tomar el código ETL heredado como código fuente (salida XML o JSON de herramientas ETL heredadas o código fuente en SQL u otros lenguajes) y acelerar el descubrimiento, evaluación, documentación e incorporación de consultores en el proyecto.
Conversión automatizada de código ETL heredado a Databricks (Python, PySpark o DBSQL): Aprovechando las últimas herramientas GenAI de manera gobernada a través de la plataforma Databricks, el código ETL heredado puede ser convertido a la plataforma Databricks y al lenguaje de ingeniería de datos preferido. Como ejemplo, algunos de estos LLMs ya vienen pre-entrenados con el sabor específico de herramientas ETL de Informatica (PowerCenter, ICDM, Data Quality, DEI).
Los aceleradores QA de SunnyData que son altamente automatizados y configurables comparan datos en el EDW heredado con los datos en el Lakehouse (esquema, tablas, columnas, tipos de datos, volumen de datos, variaciones a través de análisis estadístico) para identificar errores, pero más importante, acelerar los procesos de QA.
Conclusiones
Hemos llegado al final de esta primera parte del blog. A estas alturas, tenemos una comprensión clara de qué es Amazon Redshift, los desafíos que presenta, y por qué migrar a Databricks podría ofrecer una solución más integral mientras se mantienen sinergias clave dentro de AWS. También hemos explorado aspectos críticos de migración e iniciado la fase 1 (descubrimiento y análisis inicial).
Continuaremos con más detalles la próxima semana. ¡Gracias a todos por leer! Nos vemos la próxima semana.