Managing Data Changes with SCDs in Databricks
Why are Slowly Changing Dimensions important?
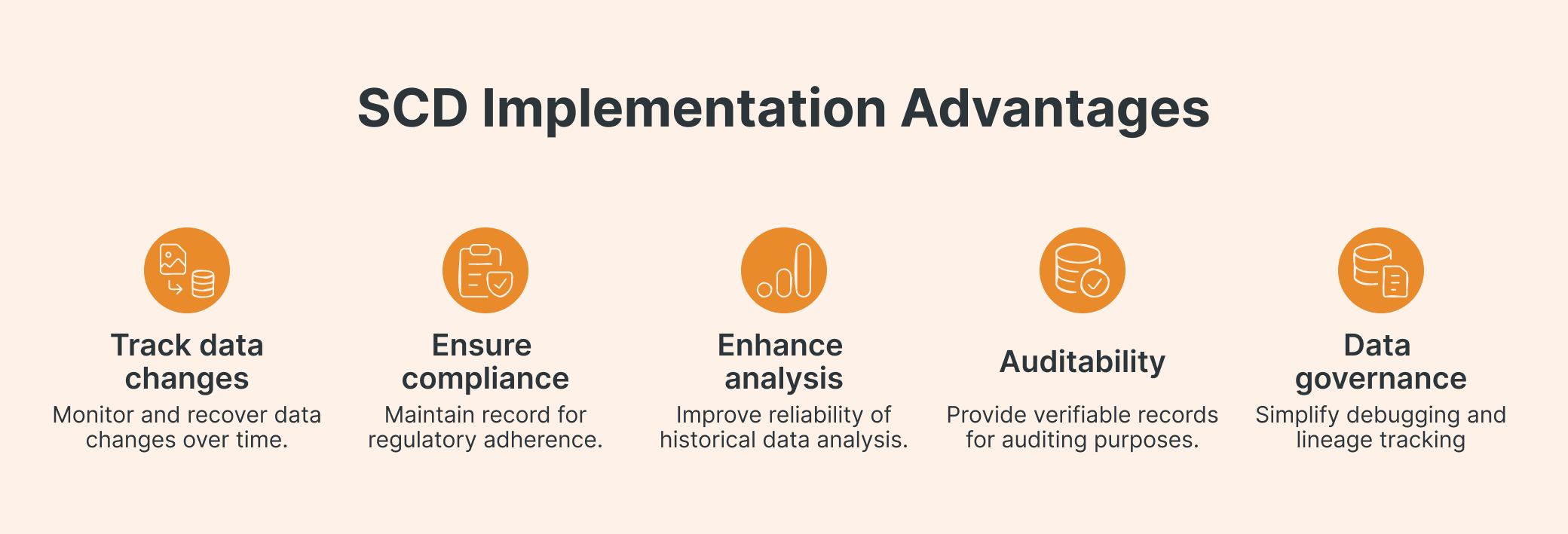
Even with all the hype around real-time streaming, Slowly Changing Dimensions (SCDs) are still crucial for building data systems you can actually trust. SCDs preserve the historical context, which is key when tracking changes in products, customers, or organizational hierarchies, all essential capabilities for modern analytics.
When you track how your data changes over time, you unlock some pretty important capabilities. You can stay compliant with regulations like GDPR and CCPA because you have accurate records of past customer states. Your historical analysis becomes way more reliable since you're anchoring metrics to the right dimensional version instead of getting misleading insights. For regulated industries, this auditability is non-negotiable (you need verifiable, time-aware records). And for data governance, understanding when and how your data changed makes debugging and lineage tracking so much easier.
Source: SunnyData
Within Databricks, implementing SCDs is not only possible but can also be done elegantly and efficiently. Thanks to the platform's support for Delta Lake, MERGE operations, and LakeFlow Declarative Pipelines, you can build modern, scalable SCD patterns that preserve historical accuracy without sacrificing performance.
In this blog, we’ll explore exactly how to implement various SCD types in Databricks using both SQL and Python APIs, leveraging the platform’s native features for robust dimensional change tracking. Let's start with the basics and break down the different SCD types.
Types of Slowly Changing Dimensions (SCD)
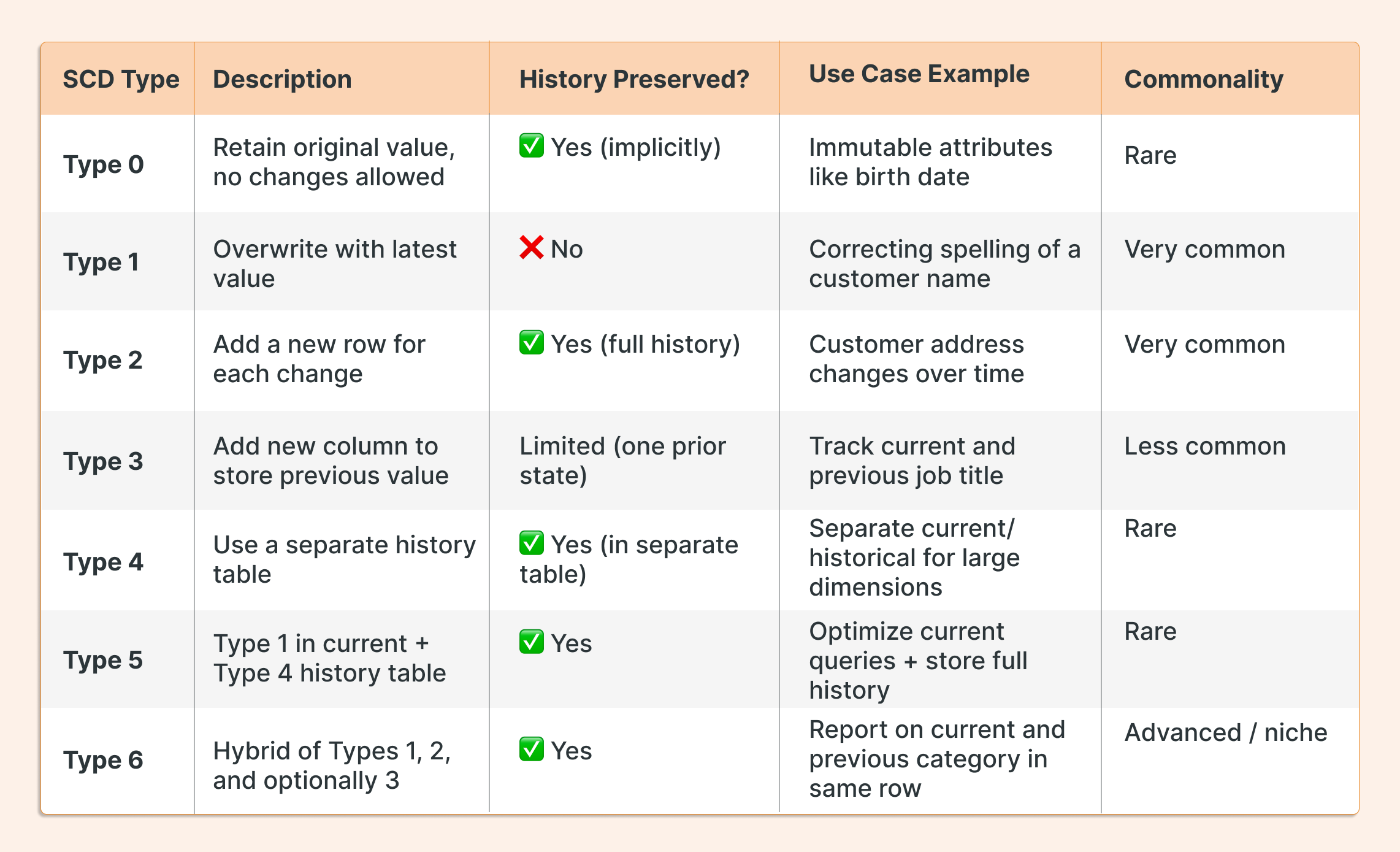
Type 0 (Retain Original) maintains the original values without tracking any changes. This works for dimension attributes that should never change, such as a customer's original registration date or a date of birth.
Type 1 (Overwrite) historical values are simply overwritten with new values. Although this approach is straightforward and requires minimal storage, it does lose historical tracking. Type 1 is good for correcting inaccurate data or for attributes where historical values aren't important.
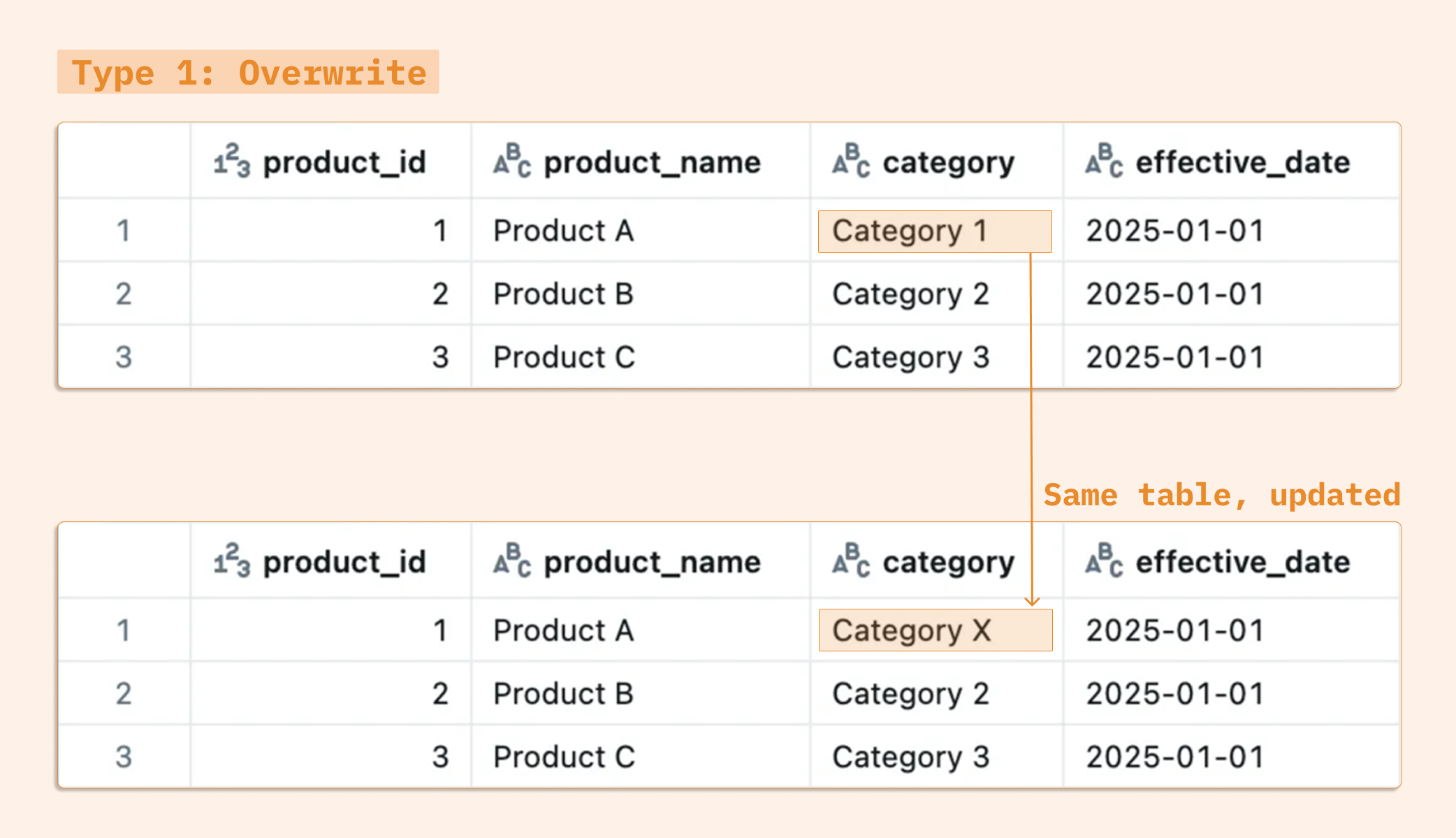
If the category for product_id = 1 changes and we don't track history, the old value is simply overwritten.
Type 2 (Add New Row) preserves the complete history by adding a new row each time an attribute changes. Each record typically includes a start date, end date, and current flag field to track when each version was active. This enables point-in-time analysis but increases storage requirements and complexity.
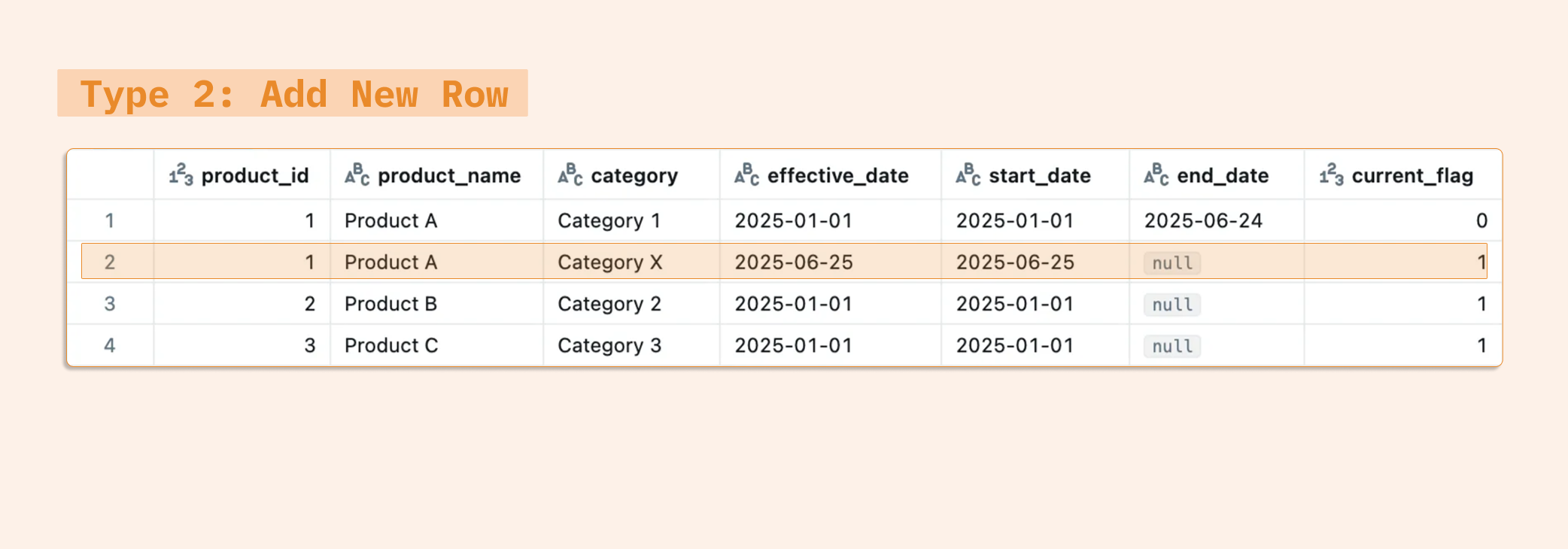
To preserve history, we keep old records defining between which dates was active
*For the end_date column, there are 2 possibilities for current data:
Keep them
nullPut a big future date such as
9999-12-31
Using a future end_date like '9999-12-31' is preferable to NULL. This approach simplifies date comparisons and makes time-based filters and joins more straightforward.
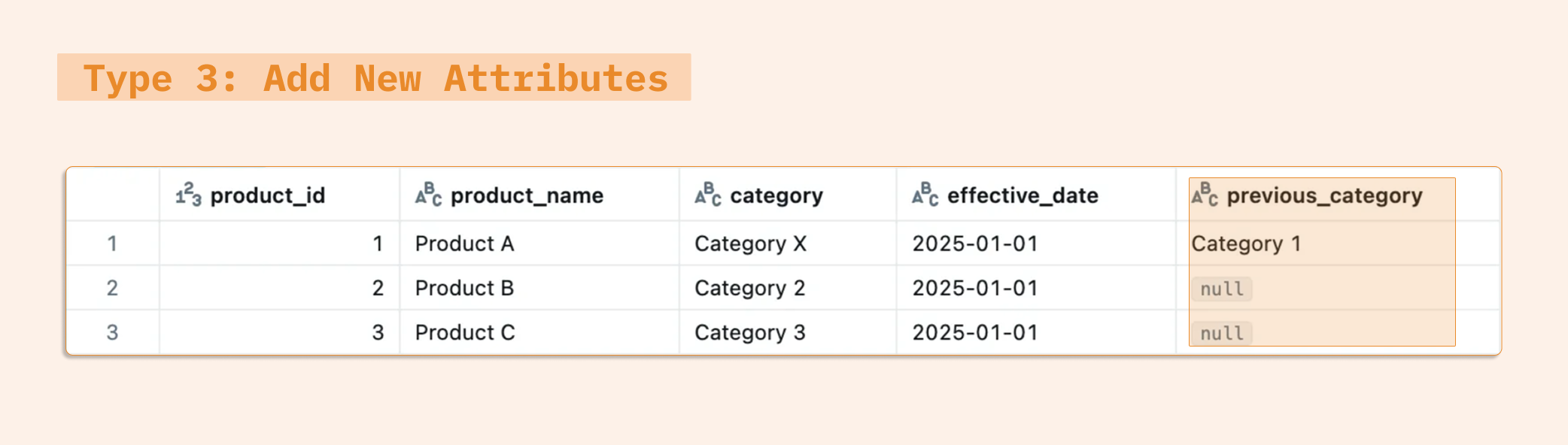
Type 3 (Add New Attributes) tracks limited history by adding new columns to store previous values. For example, a dimension might have "Current Category" and "Previous Category" columns. This approach offers a middle ground between Types 1 and 2 but only preserves one historical state.
Type 4 (History Table) uses separate tables for current and historical data. The main dimension table contains only current values, while a history table stores all previous versions. This approach optimizes query performance for current data while maintaining complete history.
Type 5 SCD combines Type 1 and Type 4 approaches. It keeps current values in a main table while storing complete history in a separate table, optimizing both query performance and historical tracking. Type 5 is ideal for high-volume environments where most queries need current data, but historical accuracy remains essential for compliance or analysis.
SCD Type 6 combines elements of Type 1, 2, and optionally 3. This allows access to current values, historical versions, and previous states in one single record. This level of flexibility can be useful in highly specialized reporting scenarios, but for many teams, it may add unnecessary complexity compared to more common patterns like SCD2 alone.
If you’re planning to implement Type 6, it can be done in different ways depending on the architecture. In this blog, we focus on the single-table approach, which combines current, previous, and versioned fields into one unified schema. However, it's also common to see two-table implementations, where one table holds current values (Type 1) and another stores full historical records (Type 2/3).
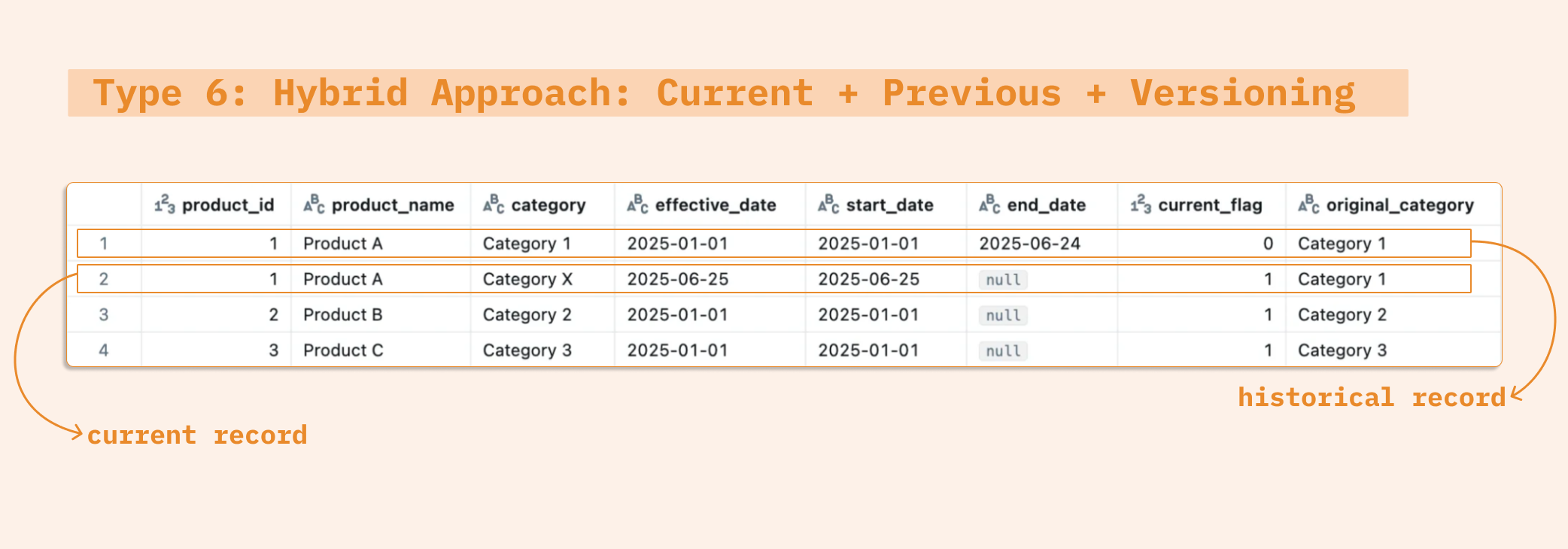
We preserve history (SCD-2), current values (SCD-1) and previous values (SCD-3)
Summary of SCD Types
Most teams rely on SCD Types 1, 2, and 3, as they offer a practical balance between simplicity and historical tracking. These types cover the majority of use cases in real-world data warehousing and analytics. While Types 4, 5, and 6 are useful in specific scenarios, they are less frequently adopted due to added complexity or storage requirements.
Source: SunnyData
Implementing SCD in Databricks
Databricks provides effective and flexible tools for managing dimension tables, whether you're working with daily batch snapshots or continuous Change Data Capture (CDC) streams. At the core of our implementation strategy, there are two key capabilities:
Delta Lake’s
MERGE INTOstatement for precise, transactional updatesThe declarative simplicity of LakeFlow Declarative Pipelines (formerly Delta Live Tables)
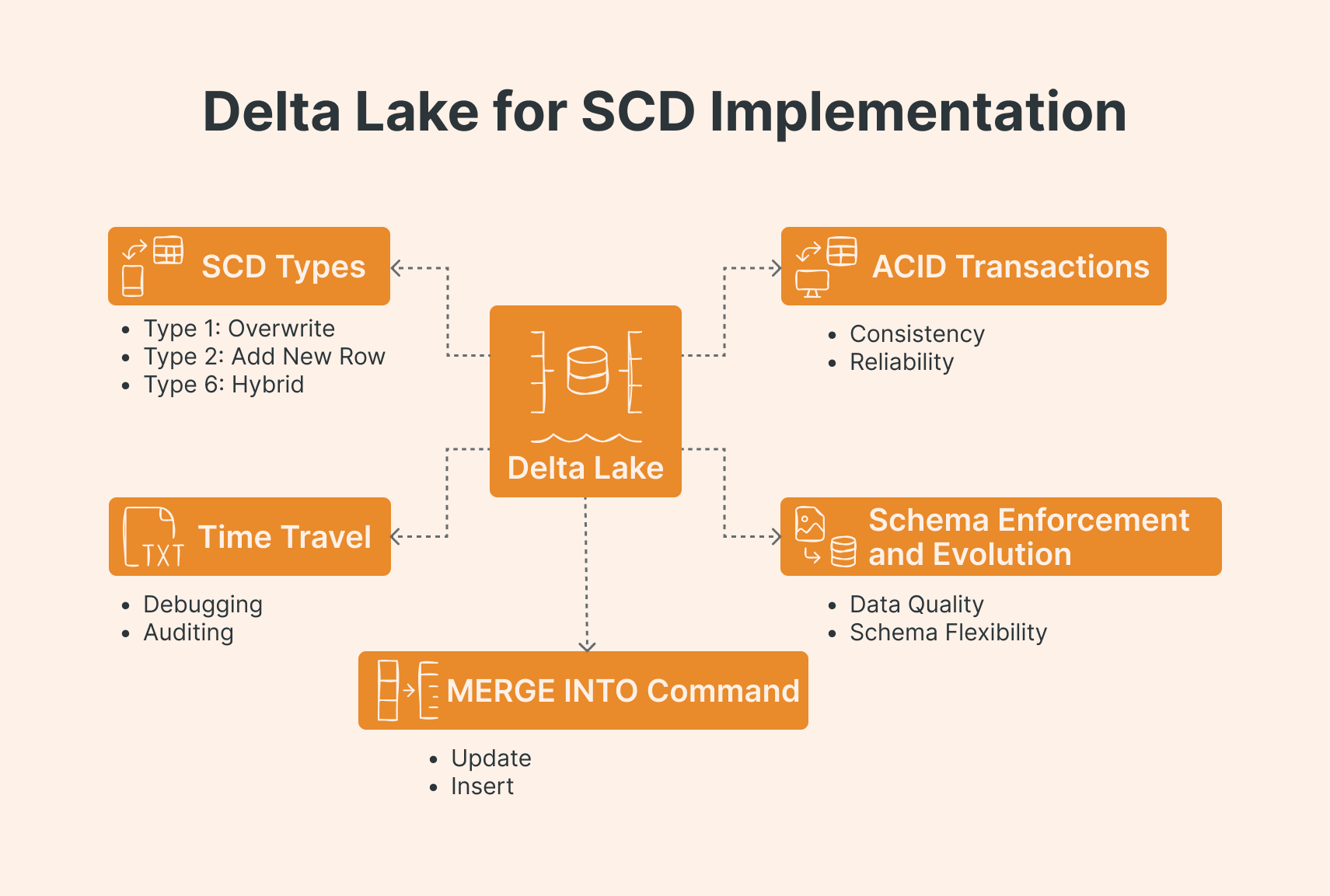
Why Delta Lake is the ideal foundation
Before moving to the code aspect, it’s worth understanding why Delta Lake is such a strong fit for implementing SCDs. First up, ACID transactions. This means your data stays consistent and reliable even when multiple processes are writing at the same time. You’ll appreciate this when you're running complex MERGE operations.
Then there's schema enforcement and evolution. Delta Lake keeps your data quality in check while still letting you evolve your dimension schema when needed. Time travel (AKA version control) is another game-changer. You can literally query previous versions of your dimension tables. This comes in super handy for debugging or when you need to do quick audits. Just keep in mind that Delta Lake keeps time-travel data for 7 days by default, so don’t rely on this for long-term tracking, you’ll still need proper SCD logic for that.
And finally, the MERGE INTO command. This is great for UPSERT operations (UPDATE or INSERT). Every SCD implementation leans heavily on this, so having it built right into Delta Lake is a huge win.
Here, we’ll focus on implementing some of the most common and practical SCD types in the field, which, as we mentioned above, are:
Type 1: Overwrite
Type 2: Add New Row
Type 6: Hybrid of Type 1, 2 & 3
Source: SunnyData
Types 1 and 2 are by far the most widely adopted, covering the majority of historical tracking needs. Type 6 is included here to illustrate a more advanced pattern that combines multiple behaviors, which are useful in more niche or complex analytical scenarios.
MERGE INTO Statement
Ideal for manual or scheduled batch jobs, especially when you need full control over merge logic or are working with snapshot-based updates.
SCD Type 1: Overwriting for the Latest View
When a dimension attribute changes, you simply overwrite the existing record. No history is preserved, which means your dimension table always reflects the current state.
-- Assume 'bronze_products' is your daily snapshot of customer data
-- Assume 'dim_products_scd1' is your SCD Type 1 dimension table
MERGE INTO dim_products_scd1 AS target
USING bronze_products AS source
ON target.product_id = source.product_id -- Your business key
WHEN MATCHED THEN
UPDATE SET
target.product_name = source.product_name,
target.category = source.category,
target.effective_date = source.effective_date,
target.last_updated = current_timestamp() -- Always update the latest
WHEN NOT MATCHED THEN
INSERT (product_id, product_name, category, effective_date, last_updated)
VALUES (source.product_id, source.product_name, source.category, source.effective_date, current_timestamp());
We match rows based on product_id.
WHEN MATCHED: If a product already exists, weUPDATEtheir attributes with the latest values from the source. Thelast_updatedtimestamp is also refreshed.WHEN NOT MATCHED: If a product is new, weINSERTa new record.
SCD Type 2: Full Historical Tracking
Since we need to preserve history, it involves adding start_date, end_date, and a current_flag to your dimension table.
A common use case for this scenario is for attributes where historical analysis is vital, such as a customer's address history (for shipping trends) or product pricing changes over time.
With this example, we are able to implement an SCD type 2 logic using only one MERGE INTO
# Assume 'bronze_products' is your daily snapshot of customer data
# Assume 'dim_products_scd2' is your SCD Type 2 dimension table
from delta.tables import DeltaTable
from pyspark.sql.functions import lit, col
# STEP 1: Identify records with newer updates for existing products
updated_records_to_insert = (
bronze_products.alias("updates")
.join(dim_products_scd2.alias("destination"), on="product_id")
.where("updates.effective_date > destination.effective_date")
.where("destination.current_flag = 1")
)
# STEP 2: Stage updates for the merge
# - Updated records to insert (new version)
# - Existing records to be expired (will match by product_id)
staged_updates = (
updated_records_to_insert.selectExpr("NULL as mergeKey", "updates.*")
.union(
bronze_products.selectExpr("product_id as mergeKey", "*")
)
)
# STEP 3: Perform the SCD2 merge
# - Expire previous records (set current_flag = false and set end_date)
# - Insert new records (new version or new product)
destination_table = DeltaTable.forName(spark, "my_catalog.my_schema.dim_product_scd2")
destination_table.alias("destination").merge(
source=staged_updates.alias("staged_updates"),
condition="destination.product_id = staged_updates.mergeKey"
).whenMatchedUpdate(
condition="""
destination.effective_date < staged_updates.effective_date
AND destination.current_flag = 1
""",
set={
"current_flag": "false",
"end_date": "staged_updates.effective_date"
}
).whenNotMatchedInsert(
values={
"product_id": "staged_updates.product_id",
"product_name": "staged_updates.product_name",
"category": "staged_updates.category",
"effective_date": "staged_updates.effective_date",
"current_flag": lit(1),
"start_date": "staged_updates.effective_date",
"end_date": lit("9999-12-31") # or null
}
).execute()
Step 1: Detects updates by comparing effective dates for the same product. Only the latest version is marked as current (
current_flag = 1).
Step 2: Prepares a union of:
Newer versions of existing products (to be inserted)
All source records (to match for potential updates)
Step 3: Executes a Delta Lake merge:
Updates the existing "current" row by expiring it (
current_flag = 0, setend_date)Inserts a new row with the updated data and marks it as current
Insert a completely new product
SCD Type 6: The Hybrid Approach
SCD Type 6 combines elements of:
Type 1: overwrites current values (for quick access to latest info).
Type 2: tracks history by versioning records (with
start_date,end_date,current_flag).Type 3 (optional): keeps some historical values (e.g., previous category in
prev_categorycolumn).
This approach is useful when you need a full history of certain attributes, but also want immediate access to the most current value of those attributes, and other attributes should simply overwrite.
Implementing SCD Type 6 is almost identical to what we did for SCD Type 2. Why? Because SCD6 is just SCD2 & overwriting the latest values (Type 1) & optionally keeping a previous value (Type 3).
The merge logic stays the same, we just need to tweak the INSERT to include columns like prev_category and current_category:
"prev_category": "destination.category", # Optional SCD Type 3 field "current_category": "source.category" # SCD Type 1 field
This way, we:
Expire the old record (SCD-2)
Insert the new one (SCD-2)
Overwrite current values (SCD-1)
Capture the previous value (SCD-3)
Lakeflow Declarative Pipelines (formerly DLT)
The MERGE INTO statement is a great fit for traditional batch workflows (especially when data arrives in periodic snapshots or pre-processed CDC loads). But some scenarios require incremental processing, either from streaming sources or micro-batches.
In these cases, Databricks LakeFlow Declarative Pipelines (formerly Delta Live Tables) offer a higher-level, declarative alternative. LakeFlow supports both streaming and batch pipelines, and is ideal for continuously ingesting and transforming data from various sources, including cloud storage (e.g., S3, ADLS), message queues (e.g., Kafka, Kinesis), and database change streams.
When to Use LakeFlow
LakeFlow handles both scheduled batch ingestion and continuous streaming pipelines. You get flexibility without having to pick sides.
For common patterns like SCD Type 1 and Type 2, you can just declare your intent (stored_as_scd_type = 2) and let LakeFlow handle all the messy details. This is a lifesaver for streaming data where events show up late or completely out of order. LakeFlow sorts it all out without you writing extra logic.
LakeFlow takes care of orchestration, retries, monitoring, and optimization automatically. Less operational headaches for you. Use LakeFlow when your data arrives continuously or incrementally and needs processing as soon as it lands.
SCD Type 1: Overwriting for the Latest View
import dlt
from pyspark.sql.functions import col, expr
# Read the streaming CDC source (products table)
@dlt.view
def products():
return spark.readStream.table("cdc_data.products")
# Declare the target streaming table
dlt.create_streaming_table("products_scd1")
# Auto-manage the SCD Type 1 merge
dlt.create_auto_cdc_flow(
target = "products_scd1",
source = "products",
keys = ["product_id"],
sequence_by = col("sequence_num"), # ensures correct ordering
apply_as_deletes = expr("operation = 'DELETE'"),
apply_as_truncates = expr("operation = 'TRUNCATE'"),
except_column_list = ["operation", "sequence_num"],
stored_as_scd_type = 1
)
Upserts by key: Keeps only the latest version of each product based on product_id.
No history is tracked: Old values are overwritten, clean and simple.
Handles deletes and truncates: Just define the expressions for those operations.
SCD1 behavior is automatic thanks to
stored_as_scd_type = 1.
SCD Type 2: Full Historical Tracking
Implementing SCD Type 2 in LakeFlow is just as easy as Type 1. The only change you need to make is:
stored_as_scd_type = 2
That single line enables Delta Live Tables (DLT) to automatically handle tracking historical versions of records, adding start_time, end_time, and is_current columns, and preserving change history with zero manual merge logic.
It’s worth mentioning that there’s no built-in stored_as_scd_type = 6 in LakeFlow. If you need SCD Type 6 behavior (a hybrid of Type 1 and 2), you'll need to build a custom transformation using SQL or Python.
Conclusion
The bottom line: picking the right SCD approach comes down to understanding your specific situation.
Think about how your data flows in. Is it batch snapshots or continuous streams? How much history do you actually need to keep? Are your users mostly looking for current data or historical trends? And if you're in a regulated industry, make sure your approach meets compliance requirements.
The good news is that Databricks gives you solid options for all scenarios:
SQL MERGE when you need full control over batch processing
LakeFlow Declarative Pipelines for streaming CDC with less complexity
Custom Python when you need maximum flexibility
Delta Lake handles the heavy lifting with ACID transactions, time travel, and optimizations. So you can focus on picking the right pattern for your use case instead of worrying about the underlying mechanics.